
Berkeley DB Java Edition
Berkeley DB Java Edition is a general-purpose, transaction-protected, embedded database written in 100% Java (JE makes no JNI calls). As such, it offers the Java developer safe and efficient in-process storage and management of arbitrary data.
Database Environments
Database environments encapsulate one or more databases. This encapsulation provides your threads with efficient access to your databases by allowing a single in-memory cache to be used for each of the databases contained in the environment. This encapsulation also allows you to group operations performed against multiple databases inside a single transaction.
Key-Data Pairs
JE stores and retrieves data using key-data pairs. The data portion of this is the data that you have decided to store in JE for future retrieval. The key is the information that you want to use to look up your stored data once it has been placed inside a JE database.
Example
// 1. Open bdb Environment
EnvironmentConfig envConfig = new EnvironmentConfig();
envConfig.setAllowCreate(true);
Environment bdbEnv = new Environment(new File("/tmp/bdb_data"), envConfig);
// 2. Open the database
DatabaseConfig dbConfig = new DatabaseConfig();
dbConfig.setAllowCreate(true);
Database db = myDbEnvironment.openDatabase(null, "db_name", dbConfig);
// 3. Writing records to bdb
String key = "key";
String value = "value";
DatabaseEntry theKey = new DatabaseEntry(key.getBytes("UTF-8"));
DatabaseEntry theData = new DatabaseEntry(value.getBytes("UTF-8"));
db.put(null, theKey, theData);
// 4. Getting records from bdb
DatabaseEntry theKey = new DatabaseEntry(key.getBytes("UTF-8"));
DatabaseEntry theData = new DatabaseEntry();
if (db.get(null, theKey, theData, LockMode.DEFAULT) == OperationStatus.SUCCESS) {
byte[] datas = theData.getData();
String value = new String(datas, "UTF-8");
} else {
// Get Failed.
}
Berkeley DB Java Edition High Availability
Berkeley DB Java Edition High Availability is a replicated, single-master, embedded database engine based on Berkeley DB Java Edition. JE HA offers important improvements in application availability, as well as offering improved read scalability and performance. JE HA does this by extending the data guarantees offered by a traditional transactional system to processes running on multiple physical hosts.
Replication Group Members
Processes that take part in a JE HA application are generically called nodes. Most nodes serve as a read-only Replica. One node in the HA application can perform database writes. This is the Master node.
The sum totality of all the nodes taking part in the replicated application is called the replication group.
Replication groups consist of electable nodes and, optionally, Monitor and Secondary nodes.
Electable nodes are replication group members that can be elected to become the group's Master node through a replication election.
Secondary nodes also have access to a JE environment, but can only serve as read-only replicas, not masters, and do not participate in elections.
Monitor nodes do not have access to a JE environment and do not participate in elections.
Note that all nodes in a replication group have a unique group-wide name.
Replicated Environments
Every electable or secondary node manages a single replicated JE environment directory. The environment follows the usual regulations governing a JE environment; namely, only a single read/write process can access the environment at a single point in time.
However, to provide for the underlying infrastructure needed to implement replication, your JE HA application must instead use the ReplicatedEnvironment class, which is a subclass of Environment. Its constructor accepts the normal environment configuration properties using the EnvironmentConfig class, just as you would normally configure an Environment object. However, the ReplicatedEnvironment class also accepts an ReplicationConfig class object, which allows you to manage the properties specific to replication.
HelperHosts
Used to join replica group
// TODO
Example
Node-1
// 1. Config Environment
EnvironmentConfig envConfig = new EnvironmentConfig();
envConfig.setAllowCreate(true);
// 2. Config replica-group-name and node identify
ReplicationConfig repConfig = new ReplicationConfig();
repConfig.setGroupName("BDB-Replica-Group-Name");
repConfig.setNodeName("Node-1");
repConfig.setNodeHostPort("127.0.0.1:9613");
// 3. Config htlper hosts, used to join the ReplicaGroup
repConfig.setHelperHosts("127.0.0.1:9613");
// 4. Open ReplicatedEnvironment
ReplicatedEnvironment repEnv =
new ReplicatedEnvironment(envHome, repConfig, envConfig);
// 5. Open the database
DatabaseConfig dbConfig = new DatabaseConfig();
dbConfig.setAllowCreate(true);
Database db = myDbEnvironment.openDatabase(null, "db_name", dbConfig);
// 6. Writing records to bdb
String key = "key";
String value = "value";
DatabaseEntry theKey = new DatabaseEntry(key.getBytes("UTF-8"));
DatabaseEntry theData = new DatabaseEntry(value.getBytes("UTF-8"));
db.put(null, theKey, theData);
// 7. Getting records from bdb
DatabaseEntry theKey = new DatabaseEntry(key.getBytes("UTF-8"));
DatabaseEntry theData = new DatabaseEntry();
if (db.get(null, theKey, theData, LockMode.DEFAULT) == OperationStatus.SUCCESS) {
byte[] datas = theData.getData();
String value = new String(datas, "UTF-8");
} else {
// Get Failed.
}
Node-2
// 1. Config Environment
EnvironmentConfig envConfig = new EnvironmentConfig();
envConfig.setAllowCreate(true);
// 2. Config replica-group-name and node identify
ReplicationConfig repConfig = new ReplicationConfig();
repConfig.setGroupName("BDB-Replica-Group-Name");
repConfig.setNodeName("Node-2");
// 3. Config htlper hosts, used to join the ReplicaGroup
repConfig.setNodeHostPort("127.0.0.1:9613");
// Same to Node-1...
// 4. Open ReplicatedEnvironment
// 5. Open the database
// 6. Getting records from bdb
Berkeley DB Java Edition High Availability In Doris
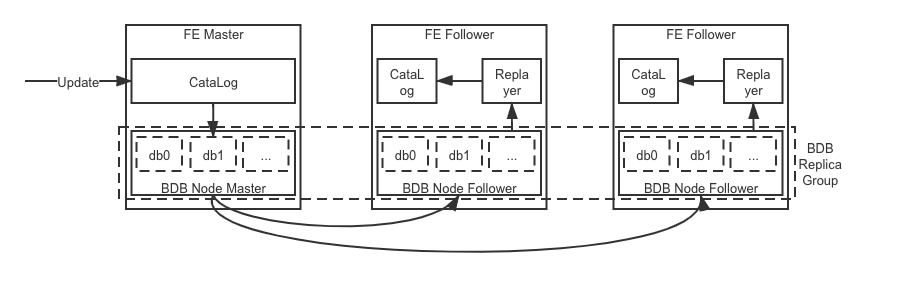
- FE 分为 MASTER/FOLLOWER/OBSERVER 节点
- 所有的写操作都会 route 到 MASTER
- FOLLOWER/OBSERVER 节点同步 MASTER 数据,并可对外提供读服务
- FOLLOEWE 节点可以参加选举,在 Master 异常时可以选举为 MASTER
- FE 中 CataLog 负责维护集群元数据,比如:Database、Table、LoadingJob 等
- 每个 FE 都内嵌了一个 BDB Node,所有 FE 的 BDB 组成一个 BDB ReplicaGroup
- Master 上元数据的每次 Update 操作会抽象成一条 Journal 写入到 BDB 中,BDB 负责将 Journal 同步到所有 Node,Journal 格式:<JournalId, Journal>,其中 JournalId 单调递增
- 每个 FE Fllower 中维护了当前已经 Replay 的 JournalID,Replayer 线程会从 bdb 中依次读取 (CurrentJournalId, MaxJournalId] 之间的 Journal 并进行回放
- FE 将 Journal 切分到了 bdb 中的多个 database 中,每个 database 只负责一段连续的 log,database 以起始 JournalID 命名,比如:
- Database named 0 contains journal 0 to journal 100
- Database named 101 contains journal 101 to journal 200
- ...
- BDB Journal database 切分的时机
- 发生 Master 切换、Master 重启
- 单个 database 中 Journal 超过一定数量时
相关文档
暂无评论...