
实现细节在 StreamTaskStateInitializerImpl.streamOperatorStateContext() 中
// -------------- Keyed State Backend -------------- keyedStatedBackend = keyedStatedBackend( keySerializer, operatorIdentifierText, prioritizedOperatorSubtaskStates, streamTaskCloseableRegistry, metricGroup); // -------------- Operator State Backend -------------- operatorStateBackend = operatorStateBackend( operatorIdentifierText, prioritizedOperatorSubtaskStates, streamTaskCloseableRegistry); // -------------- Raw State Streams -------------- rawKeyedStateInputs = rawKeyedStateInputs( prioritizedOperatorSubtaskStates.getPrioritizedRawKeyedState().iterator()); streamTaskCloseableRegistry.registerCloseable(rawKeyedStateInputs); rawOperatorStateInputs = rawOperatorStateInputs( prioritizedOperatorSubtaskStates.getPrioritizedRawOperatorState().iterator()); streamTaskCloseableRegistry.registerCloseable(rawOperatorStateInputs);
RocksDBKeyedStateBackend
基本就是从 HDFS 等拉取数据,恢复 RocksDB 的一个过程,根据是增量/全量备份的不同,恢复逻辑略有不同,入口:RocksDBStateBackend.createKeyedStateBackend
全量备份恢复
实现逻辑在 RocksDBFullRestoreOperation.restore
- 创建新的 RocksDB 实例
- 遍历所有传入的 KeyedStateHandle,打开 InputStream
- 反序列化出 StateMetaInfo
- 反序列化出所有 k-v,将属于自己 KeyGroup 的所有 k-v,写入 RocksDB
增量备份恢复
实现逻辑在 RocksDBIncrementalRestoreOperation.restore,对于 Operator 是否做了 rescale,恢复逻辑略有不同,如果做了 Rescale 的话,属于 Operator 的 KeyGroup 的 Key 有可能位于多个 RocksDB 实例中。
RestoreWithoutRescaling
这种情况下属于这个 Operator 的所有 Key 位于一个 RocksDB 实例中,恢复流程
- 打开传入的 KeyedStateHandle 的 InputStream,反序列化出 StateMetaInfo
- 将属于对应 RocksDB 的 sst 文件下载到本地
- 打开 RocksDB 实例
RestoreWithRescaling
这种情况下属于这个 Operator 的所有 Key 有可能位于多个 RocksDB 实例中,恢复流程
- 遍历所有传入的 KeyedStateHandle,选取一个初始 KeyedStateHandle,优先选取 KeyGroupRange 与自己重合度最高的,假定为 initialHandle
- 以 initialHandle 来初始 DB,恢复逻辑复用 RestoreWithoutRescaling,假定初始化后为 initialDB
- 删除 initialDB 中不属于自己 KeyGroup 的 key-value
- 遍历剩余的 KeyedStateHandle,对每个 KeyedStateHandle 做以下操作
- 打开对应的 InputStream,反序列化出 StateMetaInfo
- 将属于 RocksDB 的 sst 文件下载到临时目录
- 打开 RocksDB,scan 过滤出属于自己 KeyGroup 的 k-v 写入 initialDB
- 清理掉临时目录
HeapKeyedStateBackend
// TBD
OperatorStateBackend
具体的恢复逻辑在 OperatorStateRestoreOperation.restore 中,恢复流程
- 遍历所有传入的 OperatorStateHandle,对于每个 OperatorStateHandle 做以下操作
- 打开对应的 InputStream
- 反序列化 StateMetaInfo
- 反序列化出 Value,在内存中将 OperatorState 构建起来,两 Map
Raw State
需要自己实现 StreamOperator,实现 initializeState(StateInitializationContext context),从 Context 中拿到 State 字节流,自己解析恢复 State
public interface StateInitializationContext {
// 用于恢复 Operator Raw State
Iterable<StatePartitionStreamProvider> getRawOperatorStateInputs();
// 用于恢复 Keyed Raw State
Iterable<KeyGroupStatePartitionStreamProvider> getRawKeyedStateInputs();
}
附
三种 StateBackend 简单对比
RocksDBStateBackend
- State 访问/更新性能依赖 RocksDB + 磁盘,基本都需访问磁盘
- 快照、恢复时需要频繁的 IO 操作
- 全量备份模式
- 快照时需要全量的 scan RocksDB
- 恢复时相当于将全量的 k-v 重新做了一次插入
- 增量备份模式
- 快照时将 sst 文件拷贝到 HDFS
- 无扩缩容恢复时,将 sst 文件拷贝到本地,Open DB
- 有扩缩容恢复时,相当于 scan 多个 DB 数据,将符合条件的 k-v 做一次插入
- 全量备份模式
FsStateBackend
- State 维护在内存中,在于 TaskManager 可用内存
- 快照/恢复的性能依赖 HDFS 稳定性
MemoryStateBackend
- State 维护在内存中,在于 TaskManager 可用内存
- State 快照数据会传给 JobManager,数据量等受 JM/TM 通信框架限制
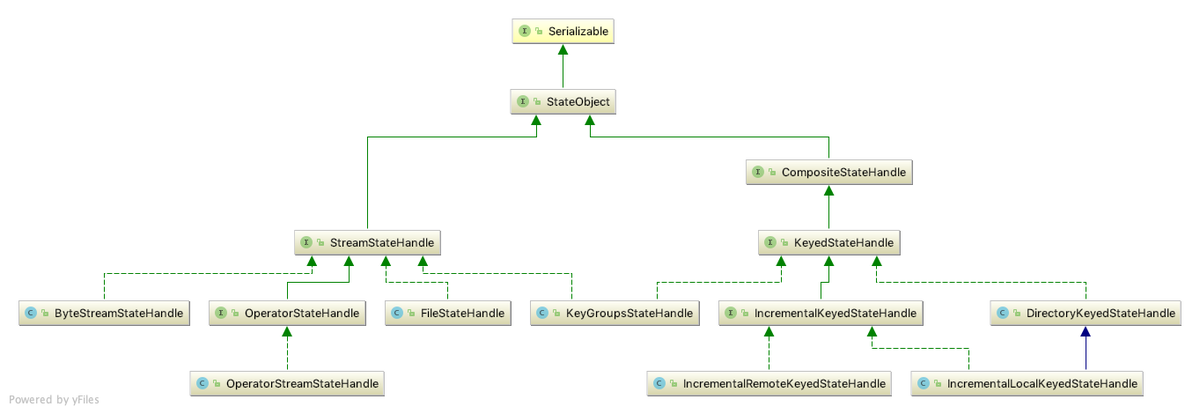
StateHandle
Checkpoint 恢复时每个 Operator 对应的 StateHandles 由 JobManager 来协调维护,包含了序列化后的 State 数据,额外的一些附加数据,比如对于增量备份模式下的 RocksDBStateBackend,StateHandle 中包含了 sst 文件的信息
KeyContext In KeyedStream
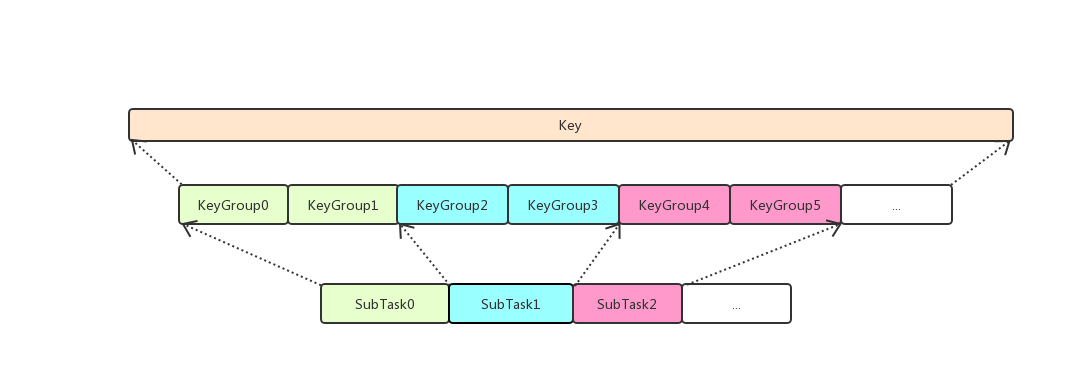
KeyGroup
为了支持 Operator 并发度变更,对于 Keyed Stream,会根据用户设定的 Max Parallelism 将 Key 划分到多个 KeyGroup 中,然后再根据 Operator 实际 Parallelism 将 KeyGroup 分配给 Operator 的各个 Task。
更新时机
Operator 收到消息后,在将消息传递给 UserFunction 之前会调用 AbstractStreamOperator.setKeyContextElement() 来更新 Operator 的 KeyContext,Operator 在更新 KeyContext 时就会记录当前的 Key 并计算出 Key 所属的 KeyGroupID,在 RocksDB 中持久化 State 数据时,会取出 KeyGroupID 和 Key 然后做一些拼接得到在 RocksDB 中实际的 key
暂无评论...